Abhinav Sharma
abhinavs@umass.edu
About Me
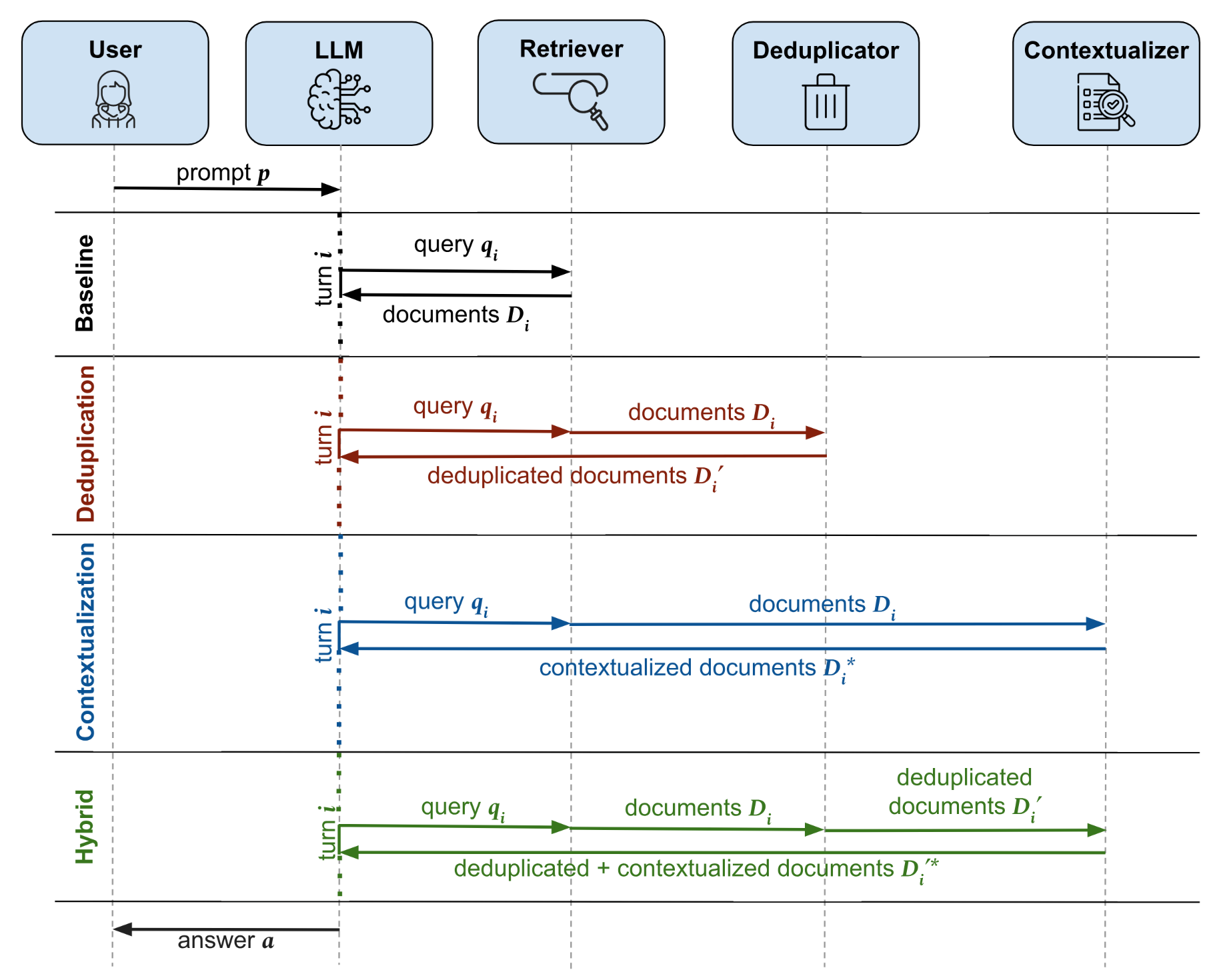
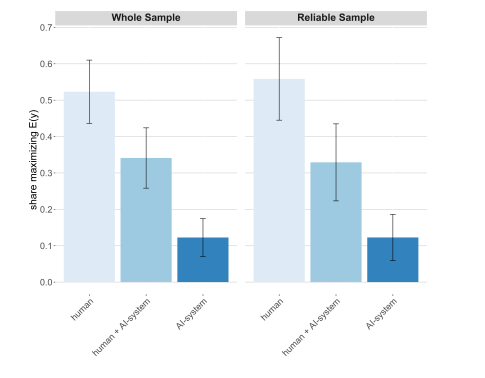
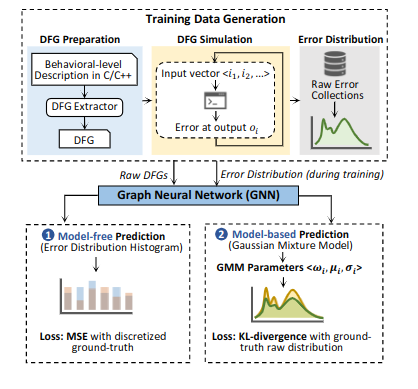
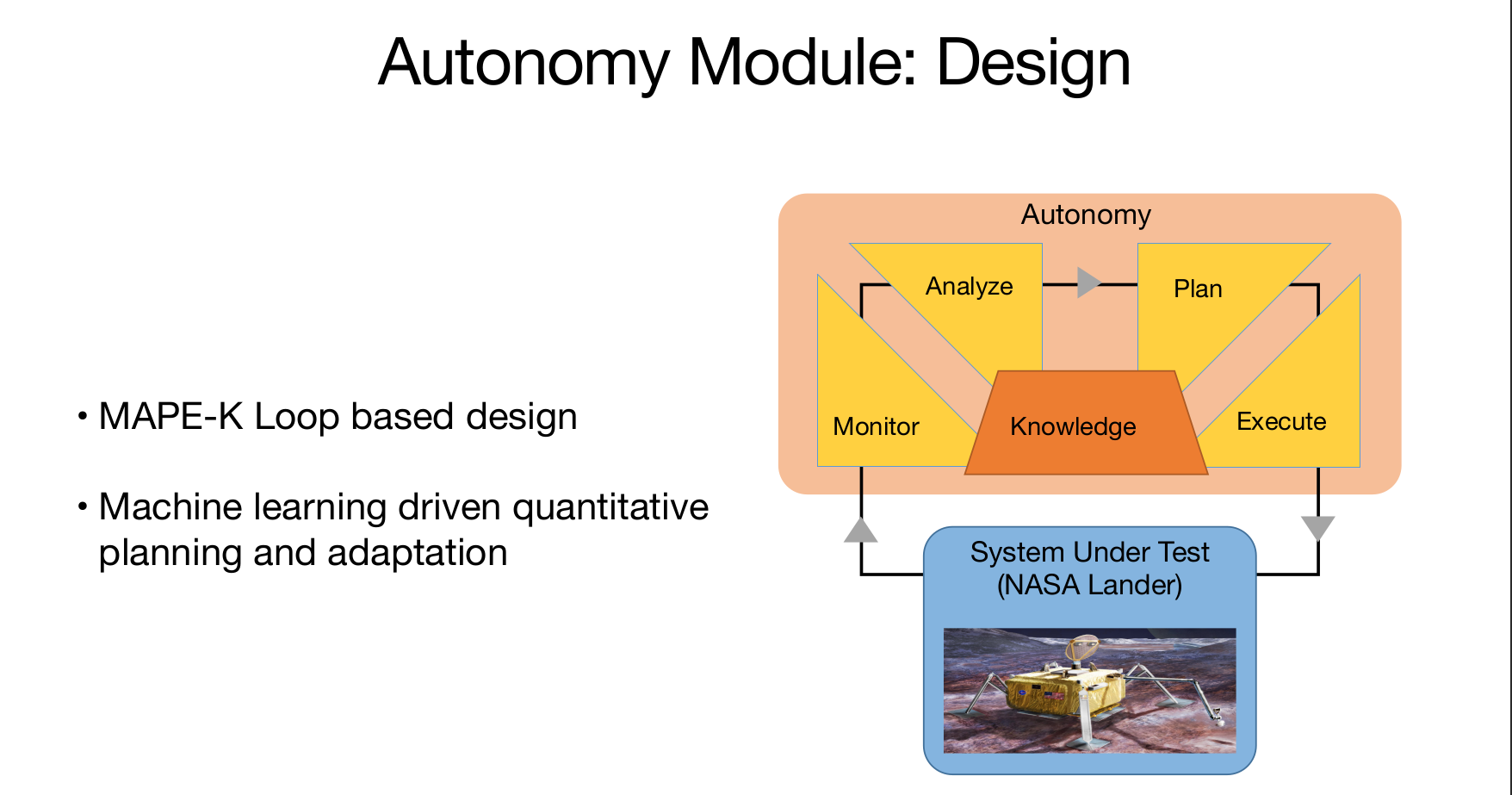
I’m an M.S. in Computer Science student at UMass Amherst with interests in machine learning research and applied AI systems. My recent work spans both research and industry, including a Research Scientist Internship at IBM, an Applied Scientist Internship at Amazon, and graduate research at Adobe. Across these experiences, I’ve worked on problems related to machine learning pipelines, model development, and the practical challenges of bringing research ideas into real-world systems.
I'm currently interested in multimodal intelligence, embodied AI, agentic systems, and robust ML. More generally, I enjoy working on problems that connect perception, reasoning, and deployment, especially when they require balancing strong research foundations with practical system design. I'm motivated by building AI that is reliable, scalable, and useful outside of idealized settings, and I hope to contribute to systems that meaningfully bridge research and real-world impact.
I believe talent and curiosity show up everywhere, even where opportunity doesn't, so I'm always happy to share advice, talk through research directions, and support students and researchers from underrepresented or less-resourced backgrounds.
|
|

|
|
| M.S. in CS UMass Amherst Sep 2024 - May 2026 |
Applied Scientist Intern Amazon Sep 2025 - Dec 2025 |
Research Scientist Intern IBM Research May 2025 - Aug 2025 |
Graduate Researcher Adobe Feb 2025 - May 2025 |