Abstract
Agentic retrieval-augmented generation (RAG) frameworks such as Search-R1 improve performance on complex, multi-hop questions by interleaving reasoning and retrieval, but they often retrieve previously seen information and struggle to integrate evidence into the current reasoning state. We study lightweight test-time modifications to Search-R1 that target these inefficiencies without changing training: contextualization of retrieved passages, de-duplication of previously seen documents, and a hybrid of both. Evaluated on subsets of HotpotQA and Natural Questions using exact match (EM), LLM-based semantic matching, and average retrieval turns, our best method — contextualization with GPT-4.1-mini — improves exact match by 5.6% and reduces retrieval turns by 10.5% relative to the Search-R1 baseline. These results suggest that improved use of retrieved evidence, rather than enforcing retrieval diversity alone, is the main driver of better answer accuracy and efficiency.
TL;DR
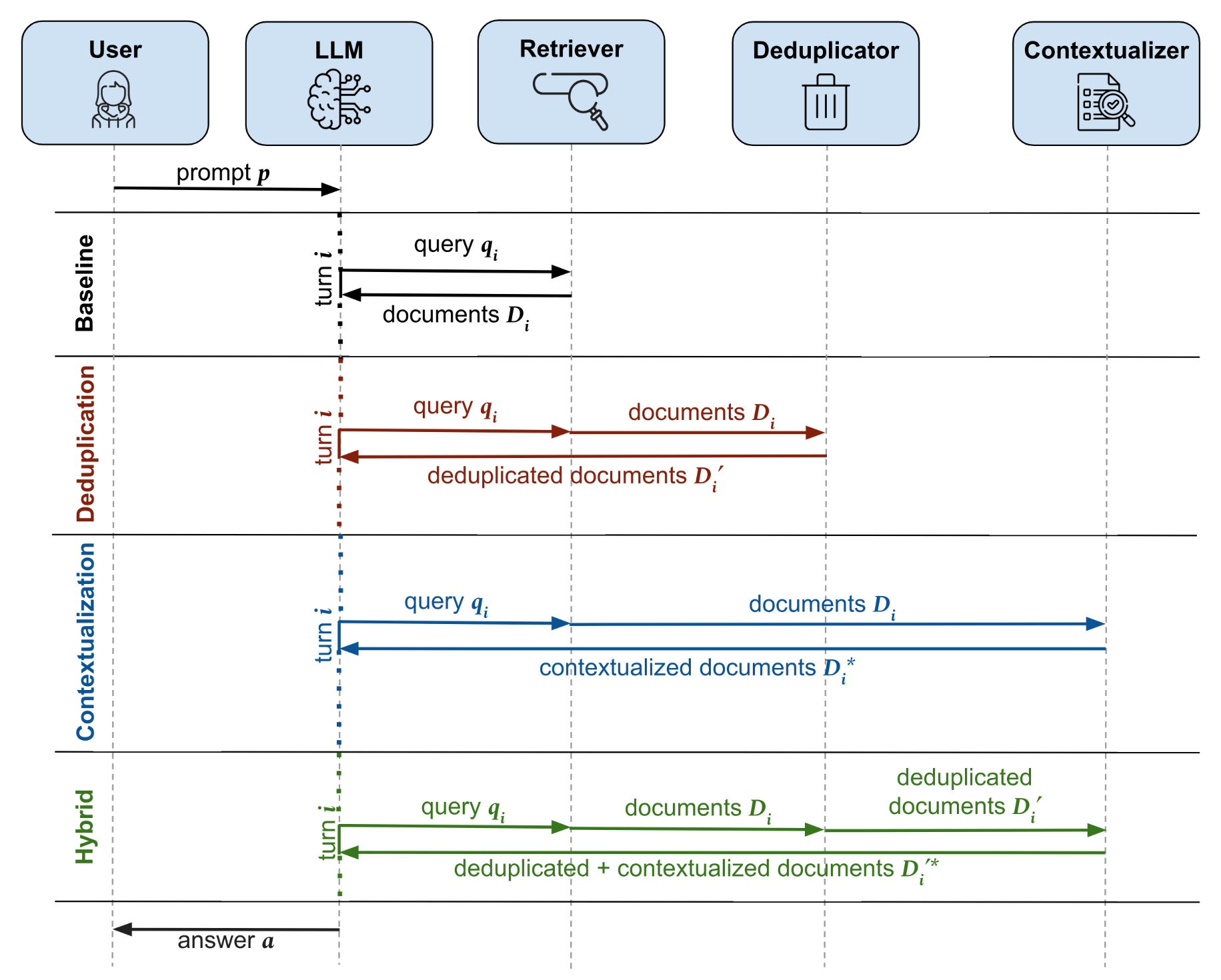
- We propose three lightweight, test-time modifications to the Search-R1 agentic RAG framework that improve answer accuracy and retrieval efficiency without retraining.
- Contextualization uses an external LLM to extract task-relevant information from retrieved documents, improving how evidence is carried across reasoning steps.
- De-duplication filters out documents already retrieved in earlier turns, encouraging contextual diversity.
- The Hybrid approach combines both modules sequentially.
- On HotpotQA and Natural Questions, our best method (Contextualization with GPT-4.1-mini) improves exact match by 5.6% and reduces retrieval turns by 10.5% relative to the Search-R1 baseline.
Key Findings
1. Improved evidence use beats retrieval diversity: When duplicates are filtered out, the model continues issuing similar queries for additional context, with little gain in accuracy. The main bottleneck is ineffective use of retrieved information, not retrieval overlap.
2. Contextualization is the most effective intervention: It is the only method that simultaneously improves Exact Match (+5.6%), LLM Match (+6.7%), and reduces the average number of retrievals (-10.5%) compared to the baseline.
3. Negative correlation between accuracy and retrieval count: Questions requiring more agentic turns are inherently more difficult, as shown by the downward trend in Exact Match score across both Search-R1 baseline and Contextualization module.
